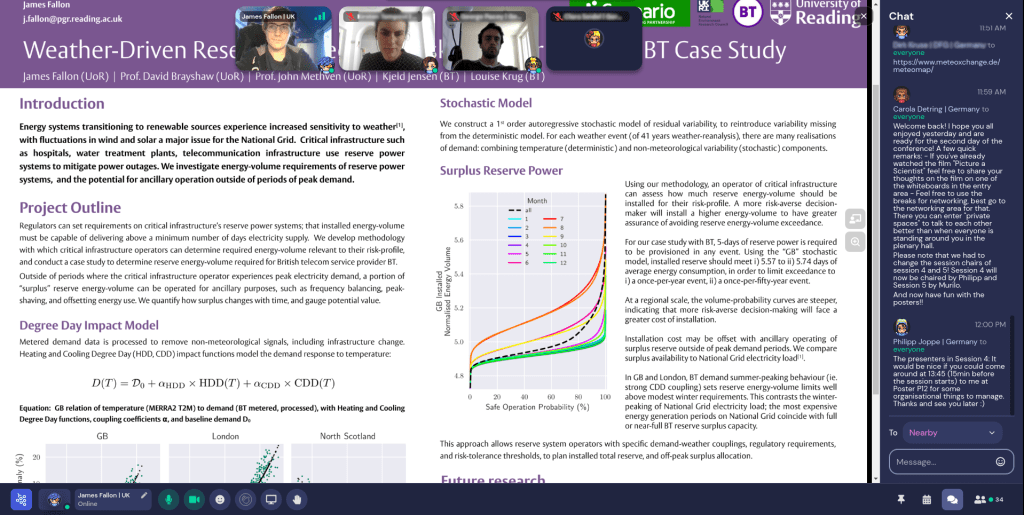
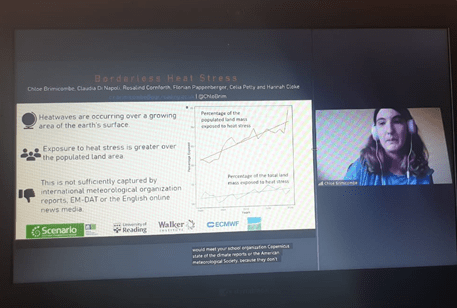
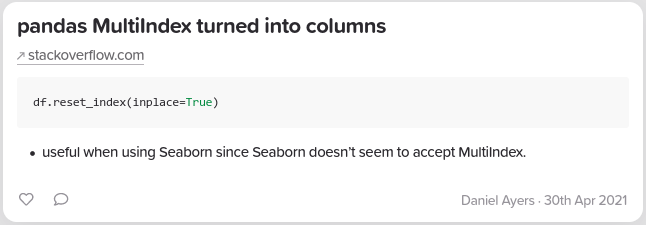
So, you’ve officially embarked on the exciting journey that is a PhD—congrats! You’ve reached a major milestone, and whether you’re feeling excited, overwhelmed, or a mix of both, just know you’ve signed up for an adventure like no other. A PhD is an incredible opportunity to dive headfirst into a subject you’re passionate about, build a toolkit of valuable skills, and—who knows?—maybe even make history in your field.
But let’s be real: it’s not all rainbows and groundbreaking discoveries. The PhD life can be challenging, sometimes feeling like a marathon through an obstacle course. You’ll have moments that test your patience, confidence, and sometimes, your sanity. That’s why here at Social Metwork, we’ve gathered some golden advice from seasoned PhD students to help you navigate these waters. Our goal? To make this transition into PhD life a little smoother, maybe even a little fun.
We’ll break these tips down into three areas: navigating day-to-day life as a PhD student, getting organized like a pro, and growing into the great scholar you’re destined to be. Ready? Let’s dive in!
1. Navigating Day-to-day Life as a PhD Student
Work-life balance
The first year of your PhD can feel overwhelming as you try to juggle research, coursework, and life. One key piece of advice? Don’t overwork yourself. As Laura Risley puts it, “Sometimes if you’re struggling with work, an afternoon off is more useful than staying up late and not taking a break.” It’s easy to get absorbed in your work, but stepping away to recharge can actually help you return with fresh perspectives.
Getting involved in activities outside your PhD is another great way to maintain balance (L. Risley, 2024). Whether it’s exploring more of Reading, participating in a hobby, or just getting outside for some fresh air, your brain will thank you for the break. Remember, “Your PhD is important, but so is your health,” so make sure to take care of yourself and make time for things that bring you joy: exercise, good food, and sleep!
Lastly, don’t underestimate the power of routine. Building a consistent schedule can help bring some stability to PhD life. Most importantly, be kind to yourself. The weight of expectations can be heavy so give yourself permission to not have it all figured out yet. You won’t understand everything right away, and that’s completely normal!
Socialising and Building a Support System
Your cohort is your lifeline. The people you start with are going through the same experiences, and they will be your greatest support system. Whether you’re attending department events, organizing a BBQ, or just grabbing a coffee, socializing with your peers is a great way to get through everything. At the end of the day, we are all in this together! As Rhiannon Biddiscombe wisely says, “Go for coffee with people, go to Sappo, enjoy the pub crawls, waste a night out at PT, take part in the panto, spend time in the department in-person” — so make sure you get involved!
If what you want is to meet new people, you could even help organise social events, like research groups or casual hangouts – feeling connected within your department can make all the difference when you’re having a tough week. And hey, if you’re looking for a fun group activity, “Market House in town has darts boards, ping pong tables, and shuffleboard (you slide little discs to the end of the board, it’s good fun!)”.
2. Getting Organised Like a Pro
Writing and Coding
Staying organised is critical for both your mental health and your research. Adam Gainford recommends you start by setting up a reference manager early on—trust us, you’ll thank yourself later. And if your research involves coding, learn version control tools like GitHub to keep your projects neat and manageable. As a fellow PhD student says “Keeping organised will help keep your future self sane (and it’s a good skill that will help you with employability and future group projects)”.
A golden rule for writing: write as you go. Don’t wait until the last minute to start putting your thoughts on paper. Whether it’s jotting down a few ideas, outlining a chapter, or even starting a draft, regular writing will save you from stress later on. Remember what Laura always says, “It’s never too early to start writing.”
Time Management
Managing your time as a PhD student is a balancing act. Plans will shift, deadlines will change, and real life will get in the way—it’s all part of the process. Instead of stressing over every slipped deadline, try to “go with the flow”. Your real deadlines are far down the road, and as long as you’re progressing steadily, you’re doing fine.
Being organised also doesn’t have to be complicated. Some find it helpful to create daily, weekly, or even monthly plans. Rhiannon recommends keeping a calendar is a great way to track meetings, seminars, and research group sessions – I myself could not agree more and find time-blocking is a great way to make sure everything gets done. Regarding your inbox, make sure you “stay on top of your emails but don’t look at them constantly. Set aside a few minutes a day to look at emails and sort them into folders, but don’t let them interrupt your work too much!”. Most importantly though, don’t forget to schedule breaks—even just five minutes of stepping away can help you reset (and of course, make sure you have some valuable holiday time off!).
3. Growing into the Scholar You’re Meant to Be
Asking for Help
This journey isn’t something you’re expected to do alone. Don’t be afraid to reach out for help from your friends, supervisors, or other PhD students. Asking questions is a sign of strength, not weakness. What’s great is that everyone has different backgrounds, and more often than not, someone will be able to help you navigate whatever you’re facing (trust me, as a geography graduate my office mates saved my life with atmospheric physics!). Whether you’re stuck on a tricky equation or need clarification on a concept, ask ask ask!
“You’ve got a whole year to milk the ‘I’m a first year’ excuse, but in all seriousness, its never too late to ask when you’re unsure!” – a fellow PhD student.
Navigating Supervisor Meetings
Your supervisors are there to guide you, but communication is key. Be honest with them, especially when you’re struggling or need more support. If something doesn’t make sense, speak up—don’t nod along and hope for the best, “they should always have your back” (it will also be very embarrassing if you go along with it and are caught out with questions…).
Also, “If you know some things you want to get out of your PhD, communicate that with your supervisors”. Open communication will help you build a stronger working relationship and ensure you get what you need from the process.
Dealing with Imposter Syndrome
Imposter syndrome can hit hard during a PhD, especially when you’re surrounded by brilliant people doing impressive work. But here’s the thing: don’t compare yourself to others. Everyone’s PhD is different—some projects lend themselves to quick results, while others take longer. Just because someone publishes early doesn’t mean your research is less valuable or that you’re behind – we are all on our own journeys.
And remember, no one expects you to know everything right away. “There might be a pressure, knowing that you’ve been ‘handpicked’ for a project, that you should know things already; be able to learn things more quickly than you’re managing; be able to immediately understand what your supervisor is talking about when they bring up XYZ concept that they’ve been working on for 20+ years. In reality, no reasonable person expects you to know everything or even much at all yet. You were hand-picked for the project because of your potential to eventually become an independent researcher in your field – A PhD is simply training you for that, so you need to finish the PhD to finish that training.”
If you’d struggling with imposter syndrome, or want to learn about ways to deal with it, I highly recommend attending the imposter syndrome RRDP.
A Few Final Words of Wisdom
The PhD rollercoaster is full of ups and downs, but remember, you’re doing fine. “If you’re supervisors are happy, then don’t worry! Everything works out in the end, even when it seems to not be working for a while! “– Laura Risley
It’s also super important to enjoy the process. You’ve chosen a topic you’re passionate about, and this is a rare opportunity to fully immerse yourself in it. Take advantage of that! Don’t shy away from opportunities to share your work. Whether it’s giving a talk, presenting a poster (or writing for the Social Metwork blog!!), practice makes perfect when it comes to communicating your research.
Embarking on a PhD is no small feat, but hopefully with these tips, you’ll have the tools to manage the challenges and enjoy the ride. And if all else fails, remember the most important advice of all: “Vote in the Big Biscuit Bracket—it’s the most important part of being a PhD student!”.
From the department’s PhDs students to you!
Written by Juan Garcia Valencia